Recent searches
Search options


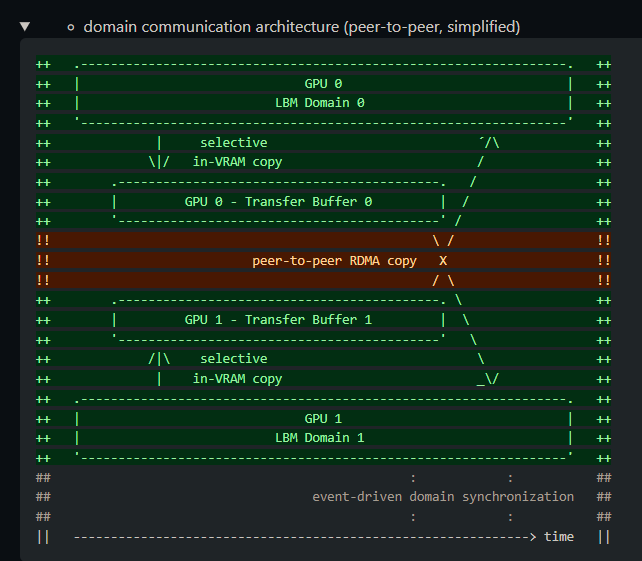
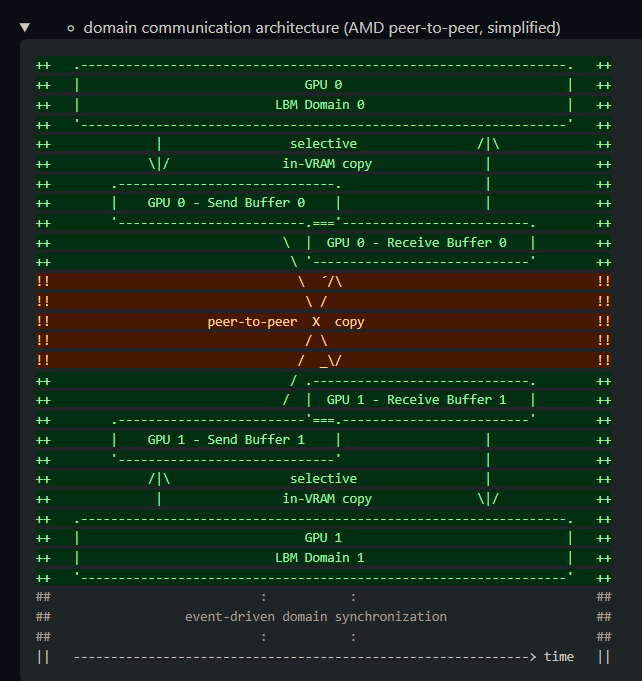


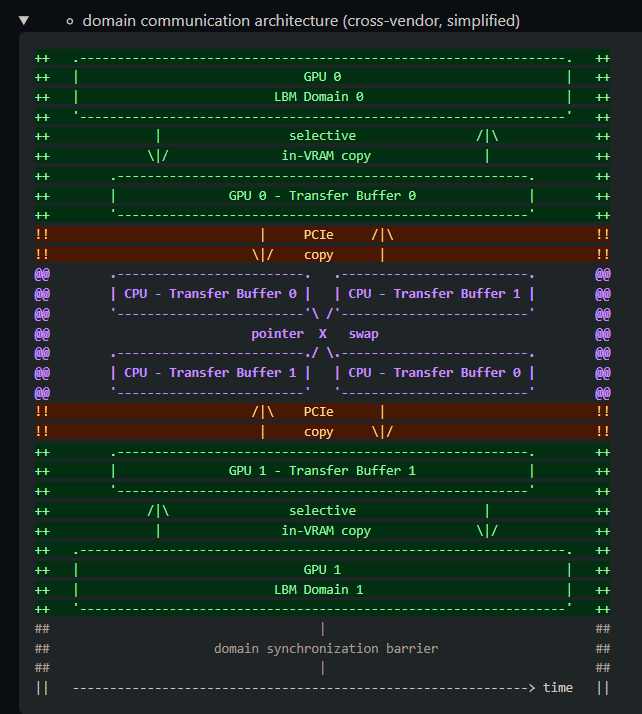
The clEnqueueMigrateMemObjects mechanism in the #OpenCL spec is too vague and should be improved. It is unclear on whether memory on the target device is extra allocated/freed. 
Better would be explicit data copy between existing buffers on source & target devices. 7/9
7/9

Credit and many thanks to Jan Solanti from Tampere University for visiting me at University of Bayreuth and testing this together with me, in his endeavour to implement/optimize #PoCL-Remote.
Thanks to @ShmarvDogg for testing P2P mode on his 2x A770 16GB "bigboi" PC!8/9
9/9
The source code for the experimental @FluidX3D P2P is available in this branch on #GitHub: https://github.com/ProjectPhysX/FluidX3D/tree/experimental-p2p
The PR for #PoCL with cudaMemcpy is available here: https://github.com/pocl/pocl/pull/1189
10/9
On PVC (4x GPU Max 1100), P2P transfer does not work either. Both the implicit and explicit #OpenCL buffer migration variants cut performance in half compared to when sending buffers over the CPU. 

@ProjectPhysX the NEC VectorEngine can do AFAIK host<--> VE p2p, VE<-->VE p2p, VE<-->Melanox p2p and i recall reading something about copying to NVIDIA GPUs.
Not sure all those are available in OpenCL though or how good the opencl support is.

@freemin7 @ProjectPhysX AFAIK there's no OpenCL support for VEC, "only" SYCL
@ProjectPhysX Sounds like they need a clever OpenCL graphics engineer to patch that ;)
Specifically on the PVC front, that means having 1100s support GPU direct RDMA over PCIe, but it also means enabling the use of the XE links